In this tutorial, you've discovered how one can begin out exploring a dataset with the Pandas Python library. You noticed the way you would entry exact rows and columns to tame even the most important of datasets. Speaking of taming, you've additionally seen a number of approaches to organize and clear your data, by specifying the info style of columns, handling lacking values, and more.

You've even created queries, aggregations, and plots structured on those. For example, you used .shape to get the type (i.e. rows, columns) of a selected numpy array applying array.shape. This attribute .shape is mechanically generated for a numpy array when it can be created. In true information evaluation work, it's unlikely that we're going to be working with short, hassle-free lists just like the one above, though. Generally, we'll must work with information units in a desk format, with a number of rows and columns. Recall that within the teachings on numpy arrays, you ran a number of features to get the mean, minimal and optimum values of numpy arrays.
![]()
This rapid calculation of abstract statistics is one advantage of utilizing pandas dataframes. You can use the tactic .info() to get particulars a few pandas dataframe (e.g. dataframe.info()) similar to the variety of rows and columns and the column names. The first tuple on every line is the form of the picture array , and the next string is the information kind of the array elements. Images are often encoded with unsigned 8-bit integers , so loading this picture and changing to an array provides the sort "uint8" within the primary case. The second case does grayscale conversion and creates the array with the additional argument "f".

This is a brief command for setting the sort to floating point. Note that the grayscale photograph has solely two values within the kind tuple; clearly it has no shade information. The format of particular person columns and rows will impression evaluation carried out on a dataset examine into Python. For example, you can't carry out mathematical calculations on a string . This may well sound obvious, nonetheless every so often numeric values are examine into Python as strings.

In this situation, if you then attempt to carry out calculations on the string-formatted numeric data, you get an error. The Origin Worksheet enables you to keep related metadata in Column Label Rows on major of the columns. Default rows contain Long Name, Units, Comments, F for Column Formula, and Sparklines that screen a miniature graph of the info within the column. Users can additional customise label rows for which includes different metadata elements. This picture exhibits customized rows with wealthy textual content formatting for super-subscript, and pictures inserted from exterior files. In this chapter, you'll discover some strategies (i.e. features precise to specific objects) which might be accessible for pandas dataframes.

The PIL perform open() creates a PIL picture object and the save() system saves the picture to a file with the given filename. The new filename would be similar to the unique with the file ending ".jpg" instead. PIL is sensible sufficient to work out the picture format from the file extension.

There is an easy examine that the file isn't already a JPEG file and a message is printed to the console if the conversion fails. Insertion or deletion of rows (adding or getting rid of components of rows /columns) is probably certainly one of the most elementary operations in Spreadsheet. In openpyxl.We can carry out these operations by only calling these strategies and passing its arguments.
When you begin engaged on any info science activity the info you're supplied isn't clean. One of probably the most typical difficulty with any info set are lacking values. Most of the machine gaining knowledge of algorithms are unable to deal with lacking values. The lacking values must be addressed earlier than continuing to making use of any machine gaining knowledge of algorithm. For ordinary operations similar to manipulating info and automating tasks, LabTalk is an effective place to start.

You can entry a wealthy set of script instructions and functions, together with an oversized assortment of X-Functions, to create scripts in your exact needs. Your customized script code could very well be readily assigned to buttons on graphs or worksheets, new toolbar buttons or customized menu items. The Data Filter function in Origin enables you to specify numeric, string, or date-time filters on a number of worksheet columns to promptly cut back data. All graphs and evaluation outcomes can mechanically replace when filter situations are modified or when the filter is enabled/disabled. The F Column Formula row in Origin worksheet enables you to instantly sort expressions to calculate column values primarily based on facts in different columns and metadata elements.
The expression might possibly be additional edited within the Set Values dialog which supplies a decrease panel to execute Before Formula scripts for pre-processing data. The Set Values dialog additionally supplies a search button to swiftly discover and insert features from over 500 built-in functions. User-defined features may even be added for customized transforms. With over one hundred built-in and prolonged graph sorts and point-and-click customization of all elements, Origin makes it straightforward to create and customise publication-quality graphs. You can add additional axes and panels, add, dispose of plots, etc. to fit your needs.

Batch plot new graphs with comparable statistics structure, or save the custom-made graph as graph template or save custom-made parts as graph themes for future use. To carry out an ANOVA, let's commence by pivoting the dataset with the cognitive potential experiment results. The pet preferences values will now be the column names, and every row will symbolize a person. Next, let's drop all of the rows that include lacking values.

By default, dropna removes rows that include lacking knowledge for even only one column. Invalid values would be much extra unsafe than lacking values. Often, you are able to carry out your knowledge evaluation as expected, however the outcomes you get are peculiar. This is particularly critical in case your dataset is gigantic or used guide entry.

Invalid values are sometimes tougher to detect, however possible implement some sanity checks with queries and aggregations. Although possible keep arbitrary Python objects within the item information type, you need to concentrate on the drawbacks to doing so. Strange values in an object column can hurt Pandas' efficiency and its interoperability with different libraries. For extra information, take a look at the official getting started out guide.
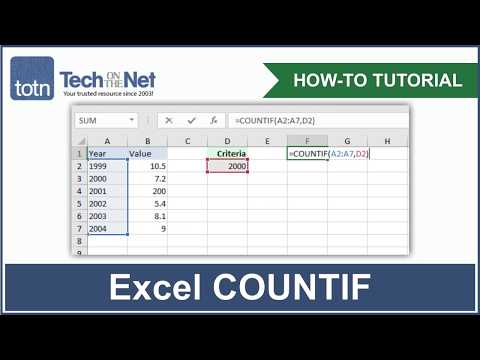
You'll see an inventory of all of the columns in your dataset and the kind of knowledge every column contains. Here, you could see the info varieties int64, float64, and object. Later, you'll meet the extra complicated categorical knowledge type, which the Pandas Python library implements itself.
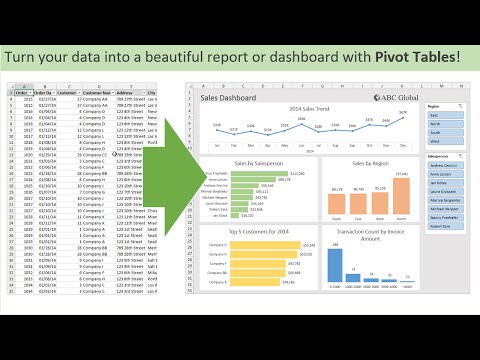
In this lesson, you will be working with the Watsi pageview data, which we first noticed within the final lesson. In the past lesson, you chose rows, columns, and files in that dataset. But how repeatedly does a specific worth seem within the identical column? The output isn't notably helpful for us, as every of our 15 rows has a worth for every column. However, this may be very helpful the place your facts set is lacking numerous values.
Using the rely system will assist to determine columns which are incomplete. From there, you could resolve whether or not to exclude the columns out of your processing or to offer default values the place necessary. To load comma-separated values knowledge into pandas we'll use the pd.read_csv() function, passing the identify of the textual content file in addition to column names that we resolve on.

We'll assign this to a variable, on this case names2015 since we're utilizing the info from the 2015 yr of delivery file. When we loaded pictures within the prior examples, we changed them to NumPy array objects with the array() name however didn't point out what that means. Arrays in NumPy are multi-dimensional and may symbolize vectors, matrices, and images.

An array is very similar to an inventory however is restricted to having all components of the identical type. Unless specified on creation, the sort will immediately be set counting on the data. Finding the lacking values is identical for each categorical and continual variables. We will use "num_vars" which holds all of the columns which aren't object files type. The best method to attain this step is thru filtering out the columns from the unique files body by files type.

By utilizing "dtypes" operate and equality operator you will get which columns are objects and that are not. Value_counts teams all of the specific situations and provides the depend of every of these instances. Again, we will use a for loop to pick out the precise column we'd like inside our knowledge set.
We'll commence by making a variable referred to as total_range the place we will shop the sum of the ranges. Then we'll write a different for loop, once more skipping the header row, and once more figuring out the second column because the selection value. One of the columns is CABIN which has values like 'A22′,'B56' and so on. First I thought to delete this column however I suppose this might be a crucial variable for predicting survivors. The Plots pane reveals all of the static graphs and pictures created in your IPython Console session. All plots generated by the code will seem on this component.
You may even be capable of save every graphic in an area file or copy it to the clipboard to share it with different researchers. And thereafter, we might entry essentially essentially the most ordinarily used options of Matplotlib with plt as shorthand. Note that this import assertion is on the submodule level. We should not importing the total matplotlib module, however a subset of it referred to as pyplot. Pyplot includes essentially essentially the most helpful options of Matplotlib with an interface that makes interactive-style plotting easier.

Submodule imports have the shape import module.submodule and you'll see them utilized in different Python libraries too sometimes. Welcome to this tutorial about knowledge evaluation with Python and the Pandas library. If you probably did the Introduction to Python tutorial, you'll rememember we briefly checked out the pandas package deal deal as a means of speedily loading a .csv file to extract some data. This tutorial appears at pandas and the plotting package deal deal matplotlib in some extra depth. When you create a brand new DataFrame, both by calling a constructor or examining a CSV file, Pandas assigns a knowledge variety to every column dependent on its values.

If you select the appropriate knowledge kind in your columns upfront, you then can greatly advance your code's performance. You can additionally desire to gain knowledge of different options of your dataset, just like the sum, mean, or ordinary worth of a gaggle of elements. Luckily, the Pandas Python library affords grouping and aggregation capabilities that will show you how to accomplish this task. Since a DataFrame consists of Series objects, you should use the exact identical resources to entry its elements.

The important distinction is the extra dimension of the DataFrame. You'll use the indexing operator for the columns and the entry strategies .loc and .iloc on the rows. While a Series is a reasonably effective info structure, it has its limitations. As you've seen with the nba dataset, which options 23 columns, the Pandas Python library has extra to supply with its DataFrame. This info construction is a sequence of Series objects that share the identical index. You have now discovered ways to run calculations and abstract statistics on columns in pandas dataframes.

On the subsequent page, you'll study varied techniques to pick out files from pandas dataframes, together with indexing and filtering of values. NumPy accommodates more than a few helpful ideas comparable to array objects and linear algebra functions. The NumPy array object can be utilized in just about all examples all by using this book. Note that the picture should be flattened first, considering the fact that hist() takes a one-dimensional array as input. The system flatten() converts any array to a one-dimensional array with values taken row-wise. The above provide the remember of lacking values in every column.

To get percent of lacking values in every column you'll divide by size of the info frame. You can "len" which provides you the variety of rows within the info frame. The Batch Processing device in Origin enables you to course of a wide variety of knowledge facts or datasets employing an Analysis Template. The template can incorporate a abstract sheet for accumulating related outcomes for every file in a abstract table.

The evaluation template can be linked to a Microsoft Word template applying bookmarks, to create customized multi-page Word or PDF reviews for every facts file. Such facts imputing will, after all, refill the dataset with information offered by cases that ought to be unseen by the mannequin whilst training. How to do away with rows from the dataset that include lacking values. It may additionally interface with databases reminiscent of MySQL, however we aren't going to cowl databases on this tutorial.

We can automate the method of performing files manipulations in Python. It's competent to spend time constructing the code to carry out these duties as a result of as soon as it's built, we will use it time and again on totally different datasets that use an analogous format. We may additionally simply share our code with colleagues they usually can replicate the identical analysis. Now that we're armed with a standard understanding of numeric and textual content files types, let's discover the format of our survey data.
We'll be working with the identical surveys.csv dataset that we've utilized in earlier lessons. You'll routinely encounter datasets with too many textual content columns. An critical talent for files scientists to have is the power to identify which columns they will convert to a extra performant files type.
![]()
Begin by importing the required Python packages after which downloading and importing facts into pandas dataframes. This is not for the reason that we did not report the place these web web page views got here from, however rather, we do not know the supply of these web web page views. Maybe an individual acquired a textual content message with a link, or typed it straight into the browser. But we do ensue to know that Watsi will get substantial visitors from e mail they ship out directly, and from different varieties of social sharing.

No comments:
Post a Comment
Note: Only a member of this blog may post a comment.